Introducción
En Chile, los titulares de proyectos con Resolución de Calificación Ambiental (RCA) están obligados a reportar datos de biodiversidad a la Superintendencia del Medio Ambiente (SMA). Esto no es voluntario: la Resolución Exenta N°343/2022 establece un formato estandarizado para que esa información se entregue a través del Sistema de Seguimiento Ambiental.
Afortunadamente, la SMA pone estos datos a disposición pública (link descarga). Son miles de registros de monitoreo, líneas base, rescates y relocalizaciones de fauna y flora, recopilados a lo largo del país. En la práctica, es una de las fuentes de información sobre biodiversidad más grandes que recién estamos empezando a analizar.
Los datos
Los archivos se distribuyen como CSV separados por punto y coma, organizados en carpetas por región y año. Cada registro incluye información sobre la campaña de muestreo (dónde, cuándo, con qué protocolo), la ubicación geográfica de las estaciones, y la identificación taxonómica de lo que se encontró: desde el reino hasta el epíteto específico, pasando por nombre común, estado del organismo y cuantificación.
La estructura es bastante completa, pero como los datos provienen de cientos de titulares distintos, es esperable encontrar inconsistencias: errores tipográficos en nombres de especies, formatos de fecha variables, coordenadas con problemas, y ese tipo de cosas que hacen que la limpieza de datos sea siempre el primer paso real de cualquier análisis.
En esta entrada veremos:
- Carga de datos: cómo leer y consolidar en R los cientos de CSV distribuidos en múltiples carpetas por región y año, y dejar todo en una estructura utilizable.
- Análisis exploratorios: una primera mirada a los datos: cobertura regional, volumen de registros y los primeros problemas que saltan a la vista.
La descripción de cada campo está disponible en el documento Descripción datos_biodiversidad.pdf
(link descarga).
Manos a la obra!
Carga de datos
El primer desafío es que los datos no vienen en un solo archivo, sino en cientos de CSV repartidos en carpetas por región y año. La estrategia es simple:
- Listar todos los archivos recursivamente,
- Leer cada uno seleccionando solo las columnas relevantes, y
- Consolidar todo en un único data frame.
Cargar todos los archivos de una vez puede ser intensivo en RAM. Si tu equipo tiene recursos limitados, prueba primero con una sola carpeta regional o un subconjunto de archivos para verificar que todo funcione antes de escalar.
Todo el código usa sintaxis y paquetes del ecosistema
tidyverse.
Las funciones se llaman con notación paquete::función()
para que siempre quede claro de dónde viene cada una.
Primero, listamos recursivamente todos los CSV dentro de la carpeta raíz:
csv_files <- fs::dir_ls(path_root, recurse = TRUE, glob = "*.csv")Luego, cada archivo se lee según las especificaciones de los metadatos (delimitado por ";"
con "." como separador decimal), seleccionando solo algunas de las columnas definidas en los
metadata. Todas las columnas se leen inicialmente como texto
(col_types = cols(.default = "c")) para evitar conflictos de tipo al consolidar
archivos donde una misma columna puede venir vacía (inferida como numérica) o con datos
(inferida como texto). Las columnas numéricas se convierten explícitamente después.
Además, se agrega el nombre del archivo y la carpeta de origen como
columnas de trazabilidad:
readr::read_delim(
f,
delim = ";",
# Según metadata: separador decimal es "." (NO ",")
# Se lee todo como character para evitar conflictos de tipo
# entre archivos (e.g. EpitetoInfraespecifico viene como
# double en archivos vacíos y character en otros)
col_types = readr::cols(.default = "c"),
locale = readr::locale(encoding = "UTF-8"),
show_col_types = FALSE
) %>%
dplyr::select(dplyr::any_of(cols_keep)) %>%
# Convertir columnas numéricas (coordenadas, medidas, valores)
dplyr::mutate(
dplyr::across(
dplyr::any_of(cols_numeric),
as.numeric
),
archivo_origen = fs::path_file(f),
carpeta_region = fs::path_file(fs::path_dir(f))
)Finalmente, se itera sobre todos los archivos con purrr::map(),
se descartan los que fallaron y se consolida todo en un único data frame:
data <- purrr::map(csv_files, read_single) %>%
purrr::compact() %>%
purrr::list_rbind()La función completa empaqueta estos tres pasos, incluyendo manejo de errores
y la opción de paralelizar la lectura con furrr si se dispone de
varios núcleos:
Ver código: función completa
read_sma_data <- function(path_root, n_cores = 1L) {
csv_files <- fs::dir_ls(path_root, recurse = TRUE, glob = "*.csv")
cli::cli_inform(glue::glue("Encontrados {length(csv_files)} archivos CSV"))
# Columnas útiles según metadata (Descripción datos_biodiversidad.pdf)
cols_keep <- c(
"CampanaSmaId", "DocumentoId", "NombreCampana", "AnoInicio",
"FechaInicio", "FechaTermino", "ObjetivoCampana",
"NombreEstacion", "TipoMonitoreo", "DescripcionEstacionReplica",
"LargoM", "AnchoM", "SuperficieM2",
"LatitudDecimalCentral", "LongitudDecimalCentral",
"LatitudDecimalInicio", "LongitudDecimalInicio",
"LatitudDecimalTermino", "LongitudDecimalTermino",
"LatitudDecimalRegistro", "LongitudDecimalRegistro",
"Region", "Provincia", "Comuna", "Localidad",
"EcosistemaNivel1", "EcosistemaNivel2", "Exposicion",
"FechaEvento", "ProtocoloMuestreo", "ProfundidadM",
"Reino", "FiloDivision", "Clase", "Orden", "Familia",
"Genero", "EpitetoEspecifico", "EpitetoInfraespecifico",
"NombreComun",
"EstadoOrganismo", "TipoCuantificacion", "Valor", "UnidadValor",
"TipoRegistro", "InformeId", "FechaExtraccion"
)
# Columnas que deben ser numéricas después de la lectura
cols_numeric <- c(
"LargoM", "AnchoM", "SuperficieM2", "ProfundidadM", "Valor",
"LatitudDecimalCentral", "LongitudDecimalCentral",
"LatitudDecimalInicio", "LongitudDecimalInicio",
"LatitudDecimalTermino", "LongitudDecimalTermino",
"LatitudDecimalRegistro", "LongitudDecimalRegistro"
)
read_single <- function(f) {
tryCatch(
{
readr::read_delim(
f,
delim = ";",
# Según metadata: separador decimal es "." (NO ",")
# Se lee todo como character para evitar conflictos de tipo
# entre archivos (e.g. EpitetoInfraespecifico viene como
# double en archivos vacíos y character en otros)
col_types = readr::cols(.default = "c"),
locale = readr::locale(encoding = "UTF-8"),
show_col_types = FALSE
) %>%
dplyr::select(dplyr::any_of(cols_keep)) %>%
# Convertir columnas numéricas (coordenadas, medidas, valores)
dplyr::mutate(
dplyr::across(
dplyr::any_of(cols_numeric),
as.numeric
),
archivo_origen = fs::path_file(f),
carpeta_region = fs::path_file(fs::path_dir(f))
)
},
error = function(e) {
cli::cli_warn(glue::glue("Error leyendo {fs::path_file(f)}: {e$message}"))
NULL
}
)
}
if (n_cores <= 1L) {
progressr::with_progress({
p <- progressr::progressor(steps = length(csv_files))
data <- purrr::map(
.x = csv_files,
.f = ~ {
result <- read_single(.x)
p()
result
}
)
})
} else {
future::plan(future::multisession, workers = n_cores)
on.exit(future::plan(future::sequential), add = TRUE)
cli::cli_inform(glue::glue("Leyendo en paralelo con {n_cores} núcleos..."))
progressr::with_progress({
p <- progressr::progressor(steps = length(csv_files))
data <- furrr::future_map(
.x = csv_files,
.f = ~ {
result <- read_single(.x)
p()
result
},
.options = furrr::furrr_options(seed = TRUE)
)
})
}
data <- data %>%
purrr::compact() %>%
purrr::list_rbind()
cli::cli_inform(glue::glue(
"✓ {nrow(data)} registros leídos de {length(csv_files)} archivos"
))
data
}Resumen general
Antes de cualquier análisis, conviene tener una vista general de lo que tenemos. Con un resumen simple podemos dimensionar el volumen de datos y detectar problemas evidentes:
general <- tibble::tibble(
metrica = c(
"Total de registros", "Total de archivos",
"Regiones únicas", "Campañas únicas",
"Documentos (EIA/DIA) únicos",
"Años cubiertos", "Rango temporal"
),
valor = c(
scales::comma(nrow(data)),
dplyr::n_distinct(data$archivo_origen),
dplyr::n_distinct(data$Region),
dplyr::n_distinct(data$CampanaSmaId),
dplyr::n_distinct(data$DocumentoId),
dplyr::n_distinct(data$AnoInicio, na.rm = TRUE),
glue::glue("{min(data$AnoInicio, na.rm = TRUE)} – {max(data$AnoInicio, na.rm = TRUE)}")
)
)| Métrica | Valor |
|---|---|
| Total de registros | 15.132.208 |
| Total de archivos | 572 |
| Regiones únicas | 24 |
| Campañas únicas | 55.245 |
| Documentos (EIA/DIA) únicos | 14.943 |
| Años cubiertos | 39 |
| Rango temporal | 1989 – 2225 |
Más de 15 millones de registros es un volumen considerable. Pero la tabla ya delata problemas: Chile tiene 16 regiones, no 24, lo que indica inconsistencias en los nombres (e.g. "Antofagasta" y "ANTOFAGASTA"), y un rango temporal que llega hasta el año 2225 confirma que hay errores de digitación en las fechas que habrá que filtrar.
Cobertura por región
Corrigiendo los nombres de región (solo eran diferencias de mayúsculas), podemos ver cómo se distribuye la cobertura de norte a sur:
Ver código: tabla de cobertura por región
# Orden geográfico norte → sur
orden_ns <- c(
"Arica Y Parinacota", "Tarapacá", "Antofagasta", "Atacama",
"Coquimbo", "Valparaíso", "Metropolitana",
"Libertador General Bernardo O'higgins", "Maule", "Ñuble",
"Biobío", "Araucanía", "Los Ríos", "Los Lagos",
"Aysén Del General Carlos Ibáñez Del Campo",
"Magallanes Y La Antártica Chilena"
)
resumen_region <- df_clean %>%
dplyr::mutate(
Region = stringr::str_to_title(Region),
Region = stringr::str_squish(Region)
) %>%
dplyr::group_by(Region) %>%
dplyr::summarise(
n_registros = dplyr::n(),
n_estaciones = dplyr::n_distinct(NombreEstacion),
n_campanas = dplyr::n_distinct(CampanaSmaId),
n_documentos = dplyr::n_distinct(DocumentoId),
.groups = "drop"
) %>%
dplyr::mutate(Region = factor(Region, levels = orden_ns)) %>%
dplyr::arrange(Region)| Región | Registros | Estaciones | Campañas | Documentos |
|---|---|---|---|---|
| Arica y Parinacota | 46.358 | 1.422 | 492 | 112 |
| Tarapacá | 2.191.196 | 17.654 | 5.174 | 894 |
| Antofagasta | 1.669.082 | 19.653 | 7.005 | 1.545 |
| Atacama | 2.475.529 | 32.126 | 4.983 | 1.759 |
| Coquimbo | 2.847.254 | 19.536 | 8.031 | 964 |
| Valparaíso | 1.129.838 | 11.502 | 4.108 | 1.247 |
| Metropolitana | 721.738 | 17.698 | 3.563 | 1.109 |
| Libertador Gral. Bernardo O'Higgins | 412.554 | 6.038 | 3.735 | 710 |
| Maule | 354.204 | 5.859 | 1.422 | 500 |
| Ñuble | 492.676 | 2.304 | 1.103 | 319 |
| Biobío | 1.496.483 | 9.489 | 5.264 | 1.638 |
| Araucanía | 178.540 | 1.711 | 1.725 | 480 |
| Los Ríos | 180.296 | 1.882 | 1.372 | 431 |
| Los Lagos | 587.395 | 4.543 | 4.820 | 1.476 |
| Aysén del Gral. Carlos Ibáñez del Campo | 82.597 | 1.196 | 1.184 | 790 |
| Magallanes y la Antártica Chilena | 266.468 | 9.315 | 2.758 | 1.336 |
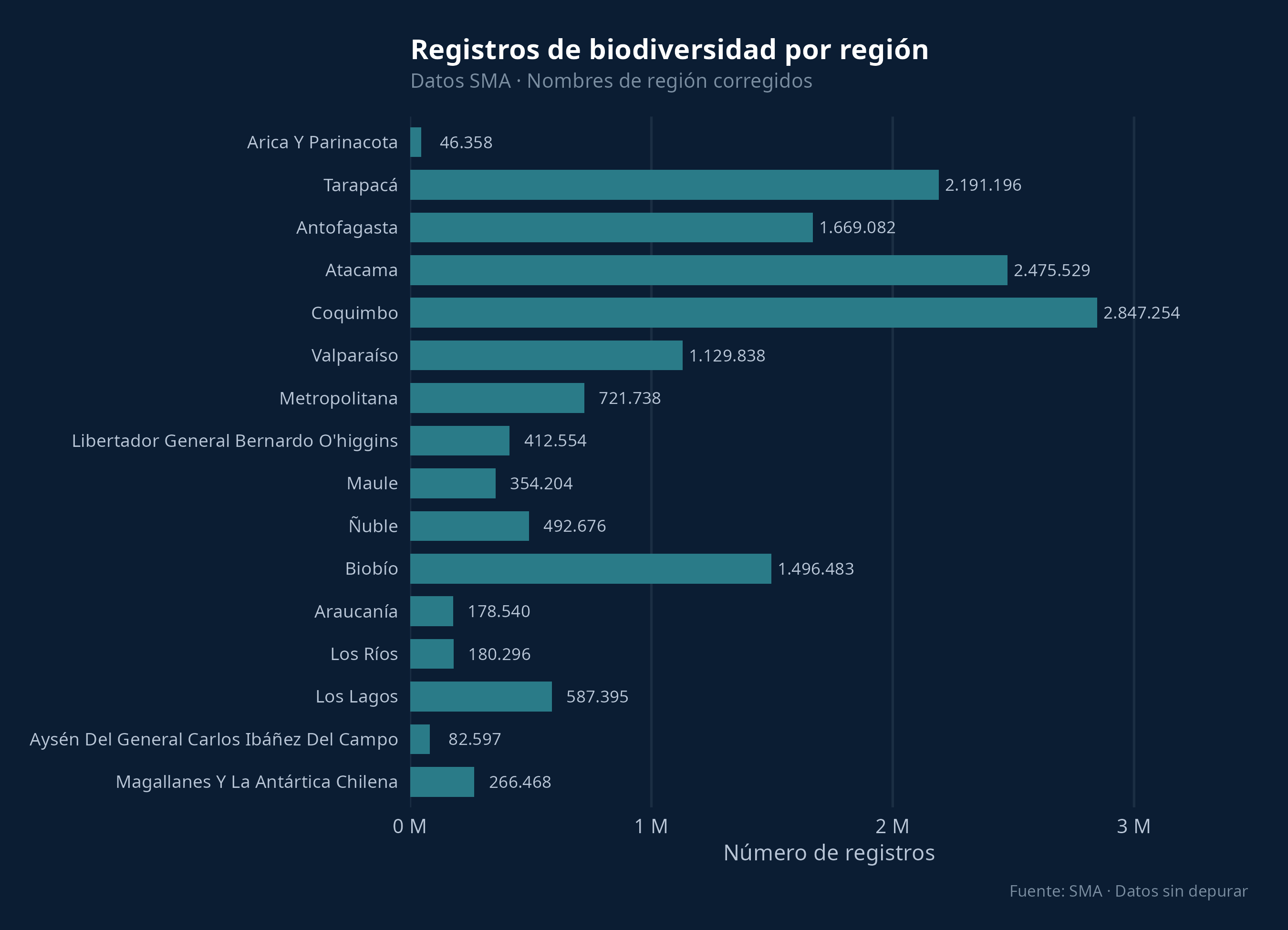
Las regiones del norte (Coquimbo, Atacama, Tarapacá) concentran la mayor cantidad de registros, lo que es esperable dado el volumen de proyectos mineros en esas zonas. Regiones como Araucanía, Los Ríos y Arica y Parinacota tienen comparativamente pocos registros.
Esfuerzo de muestreo
Para visualizar las diferencias de cobertura, dos gráficos simples: registros por región y registros por año. En ambos casos se aplicaron solo las correcciones mínimas necesarias para graficar: normalización de mayúsculas en los nombres de región, y filtro de años al rango 1990–2025. Los conteos incluyen todos los registros sin depurar.
Ver código: figuras de esfuerzo de muestreo
# ── Registros por región (barras horizontales, norte a sur) ───────────────────
p1 <- resumen_region %>%
dplyr::mutate(Region = factor(Region, levels = rev(orden_ns))) %>%
ggplot2::ggplot(ggplot2::aes(x = Region, y = n_registros)) +
ggplot2::geom_col(fill = teal, width = 0.7) +
ggplot2::geom_text(
ggplot2::aes(label = format(n_registros, big.mark = ".", decimal.mark = ",")),
hjust = -0.08, color = txt_light, size = 3
) +
ggplot2::scale_y_continuous(
labels = scales::label_number(scale = 1e-6, suffix = " M"),
expand = ggplot2::expansion(mult = c(0, 0.22))
) +
ggplot2::coord_flip() +
ggplot2::labs(
title = "Registros de biodiversidad por región",
subtitle = "Datos SMA · Nombres de región corregidos",
x = NULL,
y = "Número de registros",
caption = "Fuente: SMA · Datos sin depurar"
) +
theme_inferencia()+
ggplot2::theme(
panel.grid.major.y = ggplot2::element_blank(),
axis.text.y = ggplot2::element_text(size = 9)
)
# ── Registros por año (1990–2025) ────────────────────────────────────────────
p2 <- df_clean %>%
dplyr::filter(!is.na(AnoInicio)) %>%
dplyr::mutate(AnoInicio = as.integer(AnoInicio)) %>%
dplyr::filter(AnoInicio >= 1990, AnoInicio <= 2025) %>%
dplyr::count(AnoInicio) %>%
ggplot2::ggplot(ggplot2::aes(x = AnoInicio, y = n)) +
ggplot2::geom_col(fill = teal, width = 0.75) +
ggplot2::scale_x_continuous(breaks = seq(1990, 2025, by = 5)) +
ggplot2::scale_y_continuous(
labels = scales::label_number(scale = 1e-6, suffix = " M")
) +
ggplot2::labs(
title = "Registros por año (1990–2025)",
subtitle = "Se excluyeron años fuera de rango para eliminar errores de digitación",
x = "Año",
y = "Número de registros",
caption = "Fuente: SMA · Datos sin depurar"
) +
theme_inferencia() +
ggplot2::theme(
panel.grid.major.x = ggplot2::element_blank()
)
La distribución temporal muestra el crecimiento del sistema de reporte a lo largo de los años. Se filtraron los años fuera del rango 1990–2025 para excluir errores de digitación:
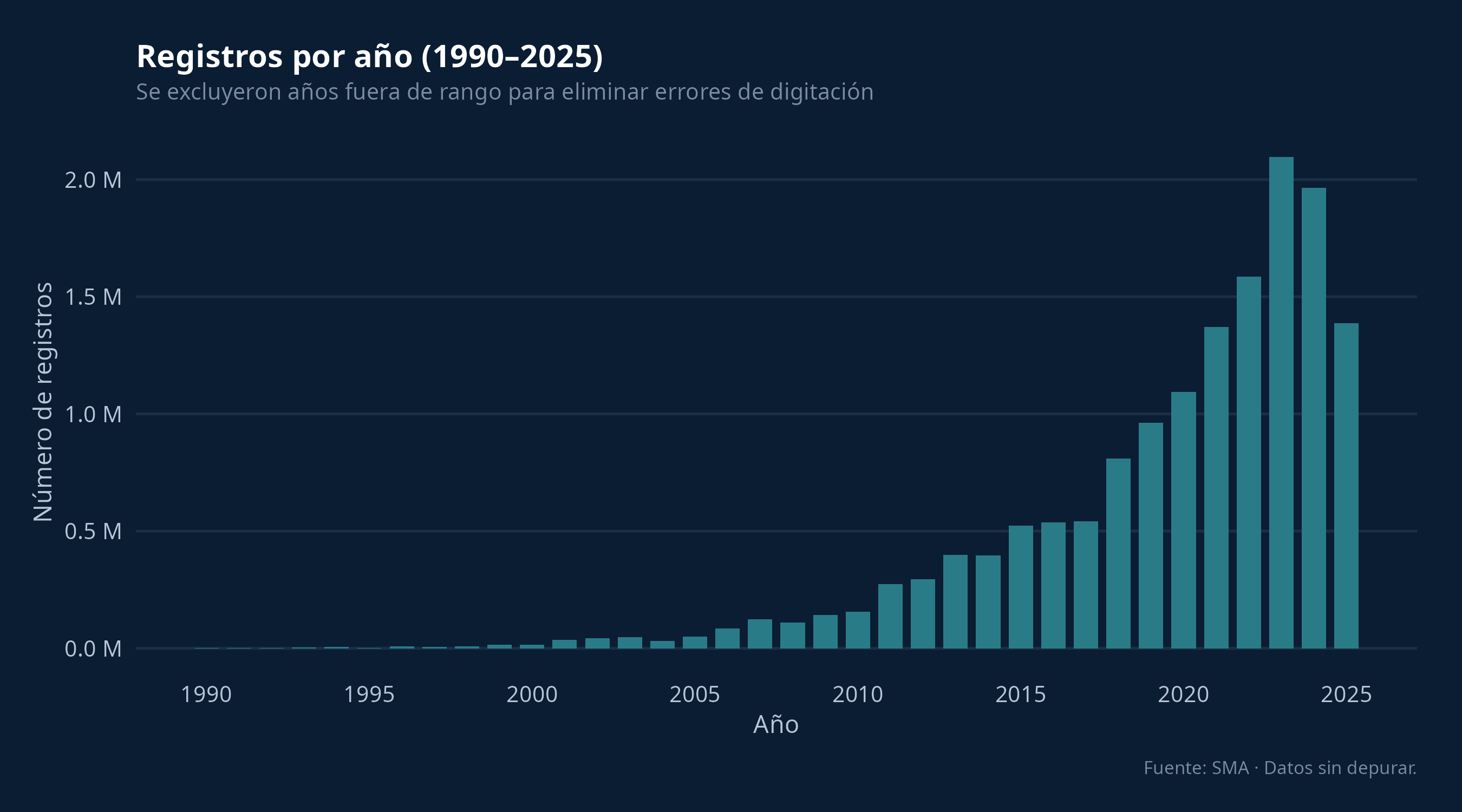
Con estos dos panoramas, regional y temporal, ya podemos identificar los primeros problemas en los datos.
Lo que ya se ve a simple vista
Con solo dos correcciones mínimas —normalizar las mayúsculas en los nombres de región y filtrar los años fuera del rango 1990–2025 para los gráficos de esfuerzo de muestreo— el exploratorio ya revela varios problemas que habrá que abordar en profundidad:
- Nombres de región inconsistentes: los datos originales contenían 24 valores únicos para 16 regiones reales, por diferencias de mayúsculas ("Antofagasta" vs. "ANTOFAGASTA"). Este problema se corrigió para los gráficos y la tabla de cobertura, pero el resto de los campos textuales no ha sido depurado.
- Fechas imposibles: el rango temporal llega hasta 2225,
indicando errores de digitación en el campo
AnoInicio. Para el gráfico temporal se filtraron solo los años entre 1990 y 2025, pero los registros con fechas erróneas siguen en la base.
Si bien no se exploraron en detalle en esta entrada, una inspección rápida de los campos taxonómicos también revela problemas evidentes:
- Campos taxonómicos con valores espurios: géneros registrados como números ("0"), epítetos como "sp" o "sp." ingresados donde debería haber un nombre real o un campo vacío.
- Niveles taxonómicos incompletos: más de un millón de registros sin Orden, pero casi todos con Clase y Familia, lo que sugiere que se saltan niveles intermedios al llenar los formularios.
- ~618.000 registros sin Reino: registros que podrían estar vacíos o mal ingresados y que requieren inspección.
Las correcciones aplicadas en esta entrada son mínimas y específicas a los gráficos presentados. Los datos no han sido depurados de forma integral: los conteos incluyen registros nulos, duplicados y posibles errores taxonómicos. Una limpieza completa es el primer paso antes de cualquier análisis formal y será abordada en las próximas entradas.
Lo que viene
Este fue un primer acercamiento general a los datos de biodiversidad de la SMA. En las próximas entradas iremos por componente, profundizando en cada uno:
- Taxonomía: limpieza básica de nombres, resolución alcanzada y una primera aproximación a la riqueza.
- Diversidad: índices, rarefacción y efecto del esfuerzo de muestreo.
- Espacial: patrones geográficos, mapas de riqueza y diversidad a lo largo de Chile.
La próxima entrada se enfoca en taxonomía, un paso necesario antes de cualquier análisis de diversidad o distribución.
← Volver al blog